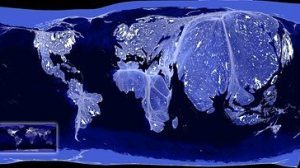
Neben den freiwillig aufgenommenen Geodaten hinterlässt ein Benutzer im Internet oft unbeabsichtigt einen geographischen Fußabdruck. Dies ist zum Beispiel immer dann der Fall, wenn Informationen – seien es Texte, Bilder oder Videos – in Echtzeit über Social Media Websites ausgetauscht werden.
{1r}
Geographischer Fußabdruck
Der Nutzer teilt diese Inhalte nicht mit dem Ziel mit, Geodaten zu erstellen – die geographische Information ist sozusagen ein Nebenprodukt, das etwa durch GPS-Empfänger in Smartphones erzeugt wird. Experten sprechen in diesem Fall von „Ambient Geographic Informations“. Beispiele sind Twitter-Feeds oder Fotos auf Plattformen wie Flickr und Instagram. Auch solche Inhalte können im Fall einer Katastrophe wichtige Informationen über die Lage und den Zustand vor Ort liefern und die Einsatzkräfte bei ihren Hilfsmaßnahmen unterstützen.
Es ist jedoch eine große Herausforderung, diese Daten automatisiert auszuwerten, zu klassifizieren und zu validieren. Dies wird derzeit mit Methoden der Informatik versucht. Darüber hinaus gibt es auch Initiativen und Plattformen wie „Ushahidi“, die für diese Aufgaben die Hilfe einer freiwilligen Crowd nutzen. Hier entstehen Synergien aus künstlicher und natürlicher Intelligenz. In der Praxis übernehmen einen großen Teil der Aufgaben oft Freiwillige aus den verschiedenen Gruppen des „Digital Humanitarian Network“.
Knackpunkt Datenqualität
Auch bei solchen Projekten ist das Fachwissen der Geoinformatiker gefragt. Die grundlegende Herausforderung heißt dabei immer: Wie kann die Qualität der Daten analysiert, bewertet und verbessert werden? Hierbei geht es zunächst um die automatische Ableitung diverser Qualitätskriterien für Geodaten: Wie genau, vollständig und aktuell sind sie – und wie konsistent bezüglich Geometrie und Semantik?
Neben diversen vergleichenden Analysemethoden haben die Heidelberger Forscher dafür mehrere Verfahren erarbeitet, die die Qualität von Geodaten aus der Historie der Datenerfassung und aus bestimmten Charakteristika der Mapper ableiten. Andere Methoden nutzen das maschinelle Lernen, um in Gebieten Geodaten zu erschließen, die bislang nicht vollständig oder nicht explizit erfasst waren. Um die Datenqualität zu verbessern, ist es beispielsweise wichtig, automatisierte Verfahren und Workflows miteinander zu kombinieren und dabei unterschiedliche Datenquellen sowie Konzepte des Crowdsourcing einzubeziehen.
Alexander Zipf, Universität Heidelberg / Ruperto Carola
Stand: 21.10.2016