Der große Vorteil: Um die Information in diesen Oligopeptiden zu kodieren, müssen sie nicht eigens produziert werden, wie bei DNA-Codes der Fall. Stattdessen zählt nur ihre An- oder Abwesenheit in der Molekülmischung – sie steht jeweils für eine 1 oder eine 0. In den Mikrogruben eines Molekülchips benötigt man so maximal acht Oligopeptide um ein Byte an Information zu speichern, so Cafferty und sein Team.
Positiv auch: Oligopeptide sind sehr robust. „Sie haben unter entsprechenden Bedingungen eine Haltbarkeit von hunderten bis tausenden Jahren“, sagen die Forscher. Denn diese Moleküle überdauern problemlos Trockenheit und Hitze und bleiben auch in Dunkelheit und ohne Sauerstoff stabil.
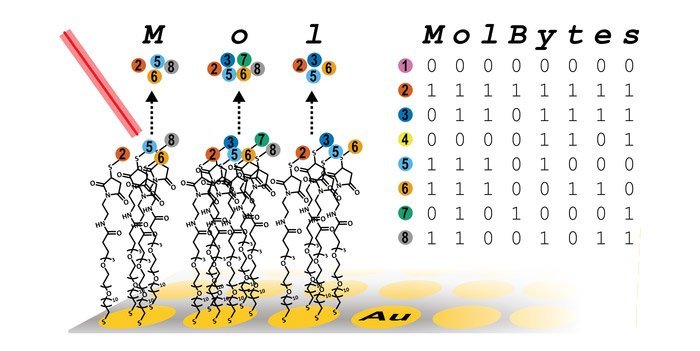
Acht Moleküle ergeben ein Byte
Für den Buchstaben „K“ beispielsweise müssen vier spezifische Moleküle im Mikrobehälter präsent sein und vier weitere Oligopeptide fehlen – das entspricht der Abfolge 01001011. „Wir konvertieren diesen Binärcode in einen molekularen Code, indem wir jedem der acht Bits ein Oligopeptid zuordnen“, erklären die Wissenschaftler. Weil jedes Molekül eine spezifische Stelle im Binärcode repräsentiert, reicht die bloße An- oder Abwesenheit der spezifischen Oligopeptide, um die Nullen und Einsen an der richtigen Stelle zu setzen.
Geschrieben wird der Oligopeptid-Code mit gängigen, computergesteuerten Laborgeräten, sogenannte Liquid Handlers, wie die Forscher berichten. Zum Lesen des Codes nutzt man ein Massenspektrometer – ein Laborgerät, das die Massen von Molekülen in beliebigen Mischungen bestimmt und auflistet. „Die Information wurde mit 99.9 Prozent Wiederherstellungspräzision geschrieben, gespeichert und gelesen“, so Cafferty und sein Team. Noch sei die Lesegeschwindigkeit dabei mit rund 20 Bits pro Sekunde eher langsam, aber das sei noch steigerbar.
Vortrag, Foto und Gemälde in Molekülen kodiert
„Diese Strategie des Schreibens und Lesens erlaubt es, mit nur einer kleinen Anzahl von Molekülen viele Formen der Information zu kodieren“, erklären die Forscher. In ersten Tests haben sie bereits den berühmten Vortrag des Physikers Richard Feynman zur Nanotechnologie mithilfe der Oligopeptide kodiert, aber auch ein Portraitfoto sowie den japanischen Holzschnitt der „Großen Hafenwelle“ von Hokusai.
Die Datendichte dieses Molekülspeichers hängt dabei von der Größe und Dichte der Mikrogruben auf dem Chip ab. In den ersten Tests lag die Datendichte nur bei 64 Bytes pro Quadratzentimeter, weil die Forscher einen gängigen Laborchip mit nur 384 Gruben nutzten. „Wir haben unser System zunächst auf Einfachheit hin entwickelt“, erklären sie. Man könnte aber auch einen modifizierten Tintenstrahldrucker verwenden, um statt der Gruben einzelne Tröpfchen als Speicherorte zu erzeugen, wie die Wissenschaftler berichten. Das würde die Datendichte stark erhöhen.
Auch mit anderen Molekülen machbar
„Theoretisch könnte damit eines Tages die gesamte öffentliche Bibliothek von New York in einem Teelöffel gespeichert werden“, so Cafferty. Wie er und sein Team erklären, haben sie zwar Oligopeptide als Modell für einen solchen Molekülspeicher verwendet. Doch auch andere kleine Moleküle mit definierten Massen seien als Informationsträger denkbar, darunter Aminosäuren, Fettsäuren oder aromatische Kohlenwasserstoffe.
Wie die Wissenschaftler betonen, sehen sie ihren Molekülspeicher aber nicht als Konkurrenz zu den schon existierenden Methoden der Datenspeicherung. „Wir sehen sie eher als Ergänzung zu diesen Technologien und als Möglichkeit für die Langzeit-Archivierung von Daten“, erklärt Cafferty. (ACS Central Science, 2019; doi: 10.1021/acscentsci.9b00210)
Quelle: Harvard University
6. Mai 2019
- Nadja Podbregar