…zu Big Data
Aber Zufallsstichproben bleiben im Kern eine Krücke. Ihnen fehlt die Detaildichte, um das zugrunde liegende Phänomen umfassend abzubilden. Unsere aus den Stichproben gewonnene Erkenntnis bleibt damit zwangsläufig detailarm. In der Regel können wir aus den Stichproben nur jene Fragen beantworten, die uns schon von Anfang an bekannt waren. Die auf Stichproben basierende Erkenntnis ist also bestenfalls eine Bestätigung oder Widerlegung einer vorab formulierten Hypothese.
Wird der Umgang mit Daten aber drastisch leichter, dann können wir in einer zunehmenden Zahl von Fällen nahezu alle Daten eines bestimmten Phänomens, das wir studieren wollen, sammeln und auswerten. Weil wir nahezu alle Daten haben, können wir auch nahezu beliebig Details analysieren.

Die Algorithmen der Suchmaschinen können Trends erkennen – sogar eine anflutende Grippewelle. © Anatoliy Babiy/ iStock.com
Google und die Grippewelle
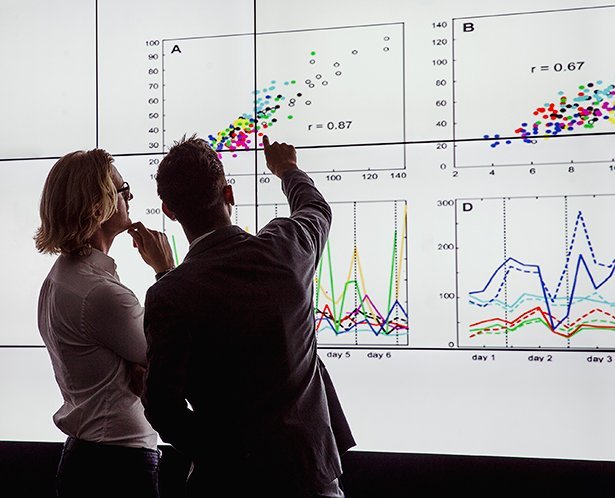
Ein Beispiel mag dies verdeutlichen: Google leitet aus Anfragen, die in seine Suchmaschine eingegeben werden, die Verbreitung von Grippe ab. Die Idee dahinter ist, dass Menschen sich zumeist dann über die Grippe informieren, wenn sie selbst oder ihnen nahestehende Personen davon betroffen sind. Eine entsprechende Analyse von Suchanfragen und historischen Grippedaten über fünf Jahre fand in der Tat eine Korrelation.
Dabei wurden 50 Millionen unterschiedliche Suchbegriffe und 450 Millionen Begriffskombinationen automatisiert evaluiert. Es wurden, mit anderen Worten, fast eine halbe Milliarde konkreter Hypothesen generiert und anhand der Daten bewertet, um daraus nicht bloß eine, sondern die optimal passende Hypothese auszuwählen. Und weil Google neben den Suchanfragen und deren Datum auch noch speicherte, von wo die Anfrage kam, konnten am Ende auch geografisch differenzierte Aussagen über die wahrscheinliche Verbreitung der Grippe abgeleitet werden.
Der Faktor Mensch
Dank Big Data können wir die Daten auch als Inspiration für neue Hypothesen einsetzen, die sich in Zukunft öfter ohne erneute Datensammlung evaluieren lassen. In einem viel diskutierten Beitrag argumentierte der damalige „Wired“-Chefredakteur Chris Anderson vor einigen Jahren, das automatisierte Entwickeln von Hypothesen mache menschliche Theoriebildung überflüssig.
Doch schon bald revidierte Anderson seine Meinung, denn so sehr Big Data in der parametrischen Generierung von Hypothesen den Erkenntnisprozess zu beschleunigen vermag, so wenig gelingen damit abstrakte Theorien. Das bleibt auch künftig den Menschen vorbehalten; der Mensch bleibt also weiterhin im Mittelpunkt der Erkenntnisschöpfung.
Das hat aber auch zur Folge, dass die Ergebnisse jeder Big-Data-Analyse durchwoben sind von menschlichen Theorien – und damit auch von deren Schwächen und Unzulänglichkeiten. So bewiesen Forscher erst vor Kurzem, dass Künstliche Intelligenzen unsere Vorurteile übernehmen, wenn sie Big Data in Form von Text-Datensätzen auswerten. Auch durch die beste Big-Data-Analyse können wir uns demnach nicht aus den daraus resultierenden möglichen Verzerrungen befreien.
In Summe lassen sich also mit Hilfe von Big Data nicht bloß bereits vorgefasste Hypothesen bestätigen, sondern automatisiert neue Hypothesen generieren und evaluieren. Dies beschleunigt den Erkenntnisprozess.
Viktor Mayer-Schönberger für bpb.de, CC-by-nc-nd 3.0
Stand: 22.06.2018
22. Juni 2018