ChatGPT ist nur ein Vertreter der neuen künstlichen Intelligenzen, die durch beeindruckende Fähigkeiten vor allem im sprachlichen Bereich auffallen. Auch Google und andere Konkurrenten von OpenAI arbeiten an solchen Systemen, auch wenn LaMDA, OPT-175B, BLOOM und Co weniger öffentlich in Erscheinung treten als ChatGPT. Das Grundprinzip dieser KI-Systeme ist jedoch ähnlich.
Lernen durch gewichtete Verknüpfungen
Wie bei den meisten modernen KI-Systemen bilden künstliche neuronale Netzwerke die Basis für ChatGPT und seine Kollegen. Sie beruhen auf vernetzten Systemen, bei denen Rechenknoten in mehreren Schichten miteinander verschaltet sind. Wie bei den Neuronenverknüpfungen in unserem Gehirn wird darin jede Verbindung, die zu einer richtigen Entscheidung führt, im Laufe der Trainingszeit stärker gewichtet – das Netzwerk lernt. Anders als bei unserem Gehirn optimiert das künstliche neuronale Netz aber nicht Synapsen und funktionelle Nervenbahnen, sondern Signalwege und Korrelationen zwischen Input und Putput.
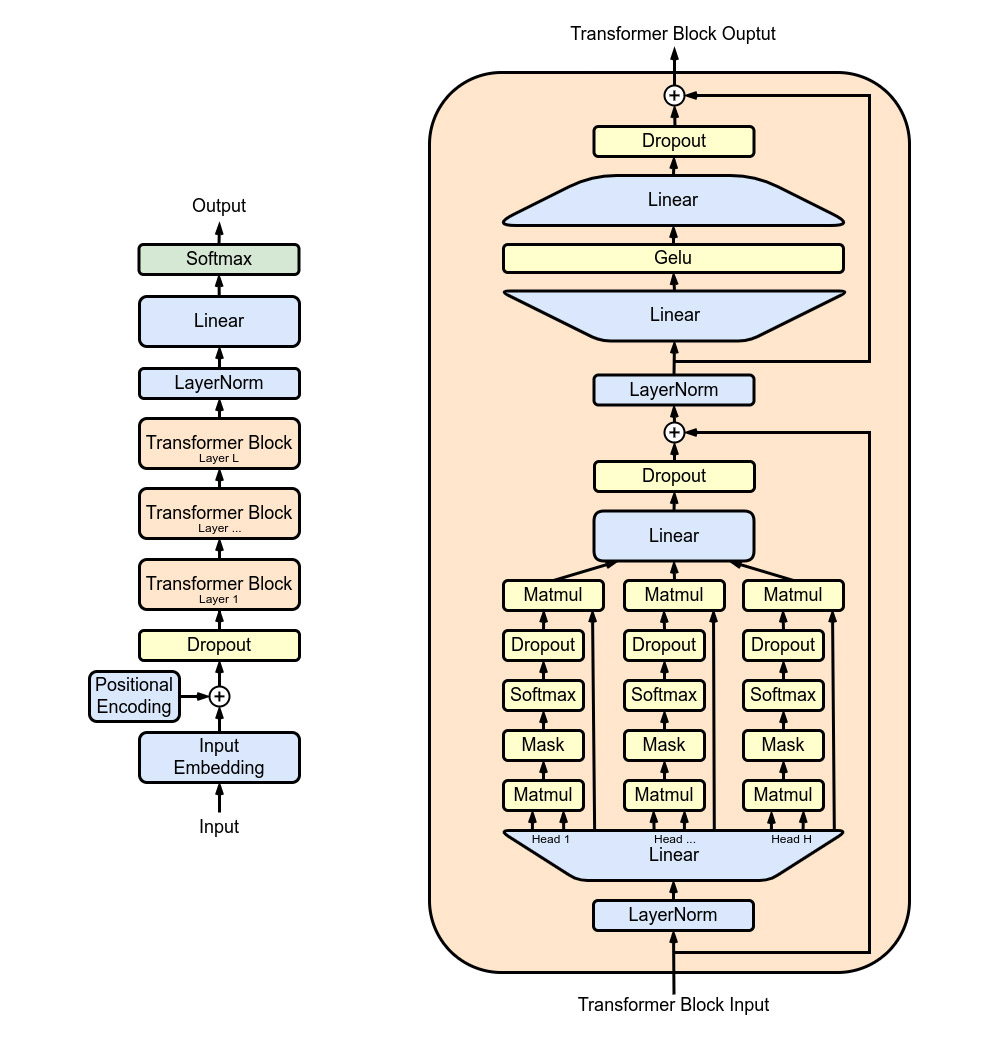
Das ChatGPT zugrundeliegende KI-System GPT-3 beziehungsweise GPT 3.5 gehören zu den sogenannten generativen Transformern. Dabei handelt es sich im Prinzip um neuronale Netze, die darauf spezialisiert sind, eine Abfolge von eingegebenen Zeichen in eine andere Zeichenfolge als Output zu übersetzen. Bei einem Sprachmodell wie GPT-3 entsprechen die Zeichenfolgen den Sätzen in einem Text. Die KI lernt durch Training auf Basis Millionen Texten, welche Wortfolgen grammatikalisch und inhaltlich am besten zur eingegebenen Frage oder Aufgabe passen. Im Prinzip bildet die Struktur des Transformers dabei menschliche Sprache in einem statistischen Modell ab.
Trainingsdatensatz und Token
Um dieses Lernen zu optimieren, hat der generative Transformer hinter ChatGPT ein mehrstufiges Training durchlaufen – er ist, wie sein Namenskürzel schon verrät, ein generativer vortrainierter Transformer (Generative Pre-trained Transformer, GPT). Die Basis für das Training dieses KI-Systems bilden Millionen Texte, die zu 82 Prozent aus verschiedenen Kompilationen von Internetinhalten stammen, 16 Prozent kommen aus Büchern und drei Prozent aus Wikipedia.