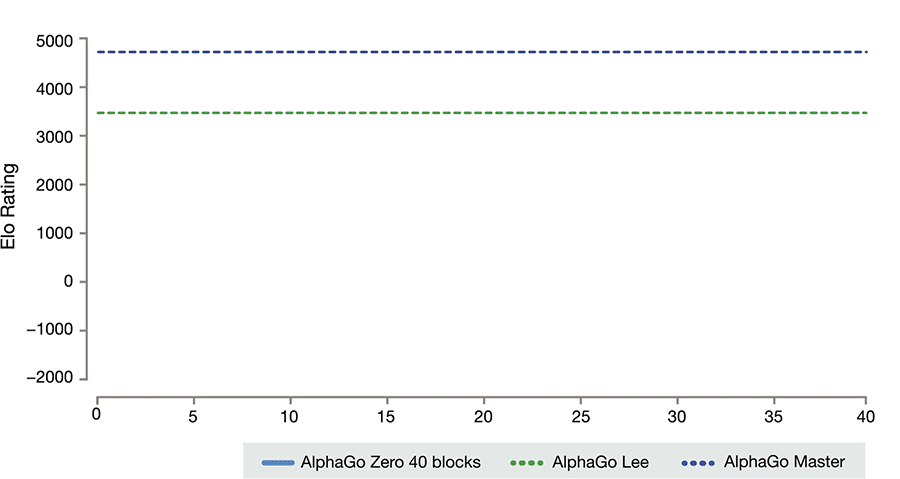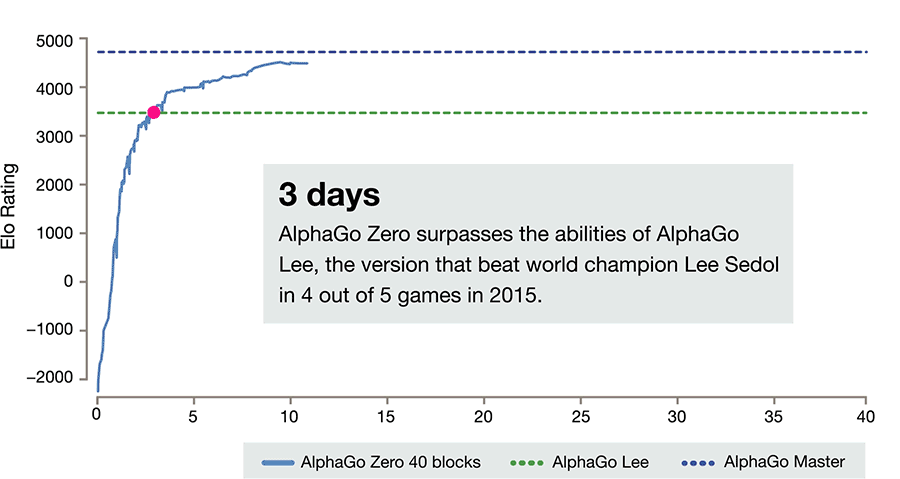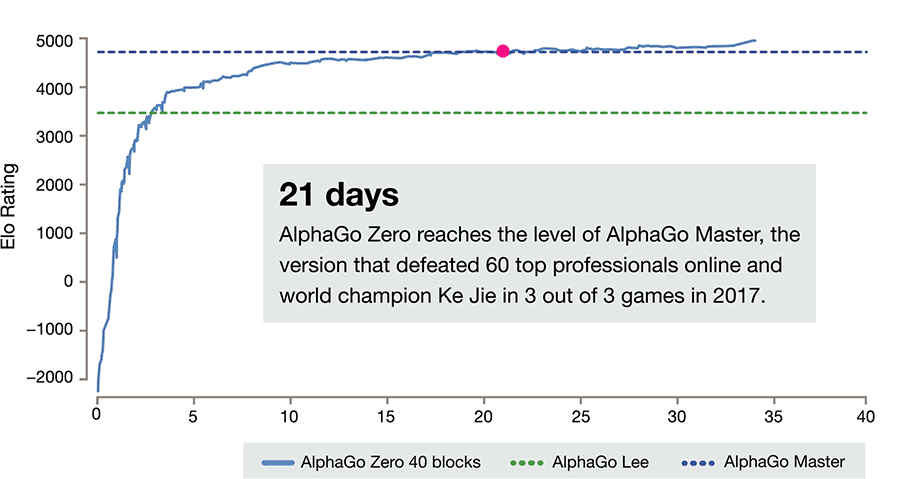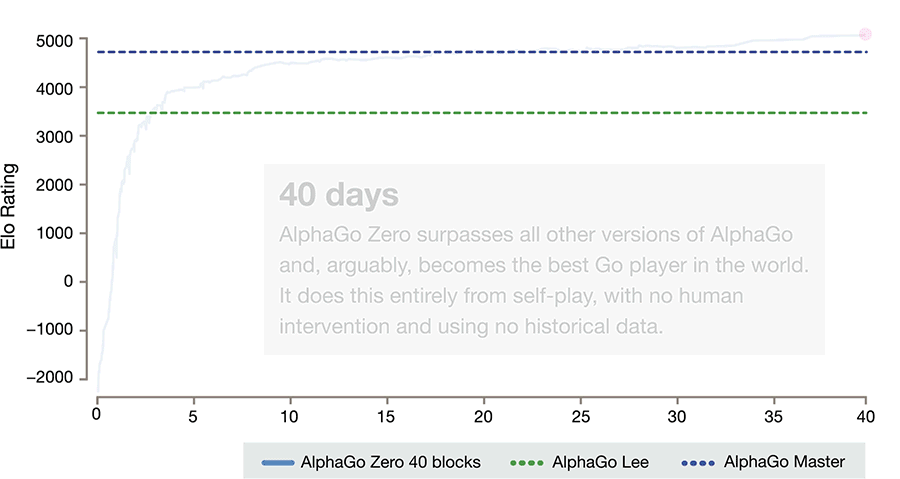
Go-Meister in nur drei Tagen: Forscher haben eine künstliche Intelligenz geschaffen, die hochkomplexe Fähigkeiten wie das Go-Spiel ganz ohne menschliche Lehrer lernen kann – und das verblüffend schnell und gut. Schon nach drei Tagen besiegte AlphaGo Zero seinen Vorgänger, der 2016 den Weltchampion im Go geschlagen hatte, wie die Wissenschaftler im Fachmagazin „Nature“ berichten. Sie sehen in solchen eigenständig lernenden Programmen die Zukunft der KI.
Kaum ein Technologiebereich hat in den letzten Jahren so rasante Fortschritte erlebt wie die Künstliche Intelligenz. Dank neuronaler Netze sind diese Programme heute lernfähig und flexibel genug, um unsere Sprache zu erkennen, als Webbots Internetseiten zu pflegen oder sogar Medizinern bei Diagnosen zu helfen.
Für besonderes Aufsehen sorgte 2015 der Sieg der Künstlichen Intelligenz AlphaGo in einem der schwersten Strategiespiele überhaupt: dem asiatischen Brettspiel Go. Nach monatelangem intensivem Training mit menschlichen Experten und Spielen gegen sich selbst konnte das Programm erstmals einen menschlichen Profi in diesem Spiel besiegen.
Lernen ohne menschliche Lehrer
Jetzt sind die Macher von AlphaGo noch einen Schritt weitergegangen: Sie haben AlphaGo so verändert, dass das KI-Programm nun das Go-Spielen komplett ohne Training mit menschlichen Spielpartnern lernen kann. Nur die Spielregeln werden ihm vorgegeben, den Rest erledigt die KI selbstständig – indem sie Millionen Male gegen sich selbst spielt.