Erbmolekül als Verschlüsselungshelfer: Die meisten echten Zufallszahlen werden heute mithilfe physikalischer Prozesse generiert. Doch auch die DNA-Synthese eignet sich als Zufallszahlengenerator, wie nun ein Experiment belegt. Dabei erzeugt die zufällige Abfolge der Basen in kurzer Zeit Millionen Gigabyte an Zufallszahlen. Dies ist das erste Mal, dass echte Zufallszahlen dieser Größenordnung auf chemischer Basis erzeugt wurden, wie Forscher im Fachmagazin „Nature Communications“ berichten.
Zufallszahlen werden für die Verschlüsselung von Daten benötigt, aber auch in der Statistik und Simulation. Diese Zahlen in der nötigen Länge und Geschwindigkeit zu produzieren, ist jedoch aufwändig. Zwar gibt es Zufallszahlengeneratoren, die mithilfe spezieller Algorithmen solche Zahlenfolgen generieren. Weil sie aber einem festen, reproduzierbaren Verfahren folgen, sind ihre Zahlen nicht komplett unberechenbar und daher für die Kryptografie nicht geeignet.
Um wirklich zufällige Zahlenfolgen zu erzeugen, nimmt man daher meist physikalische Prozesse zu Hilfe. Das können radioaktive Zerfallsprozesse sein, aber auch das atmosphärische Rauschen, Fluktuationen in einem Laser, winzige Spannungsschwankungen in einem Stromleiter oder auch der Zustand verschränkter Photonen in einem Quantensystem.
Abfolge der vier DNA-Basen als Grundlage
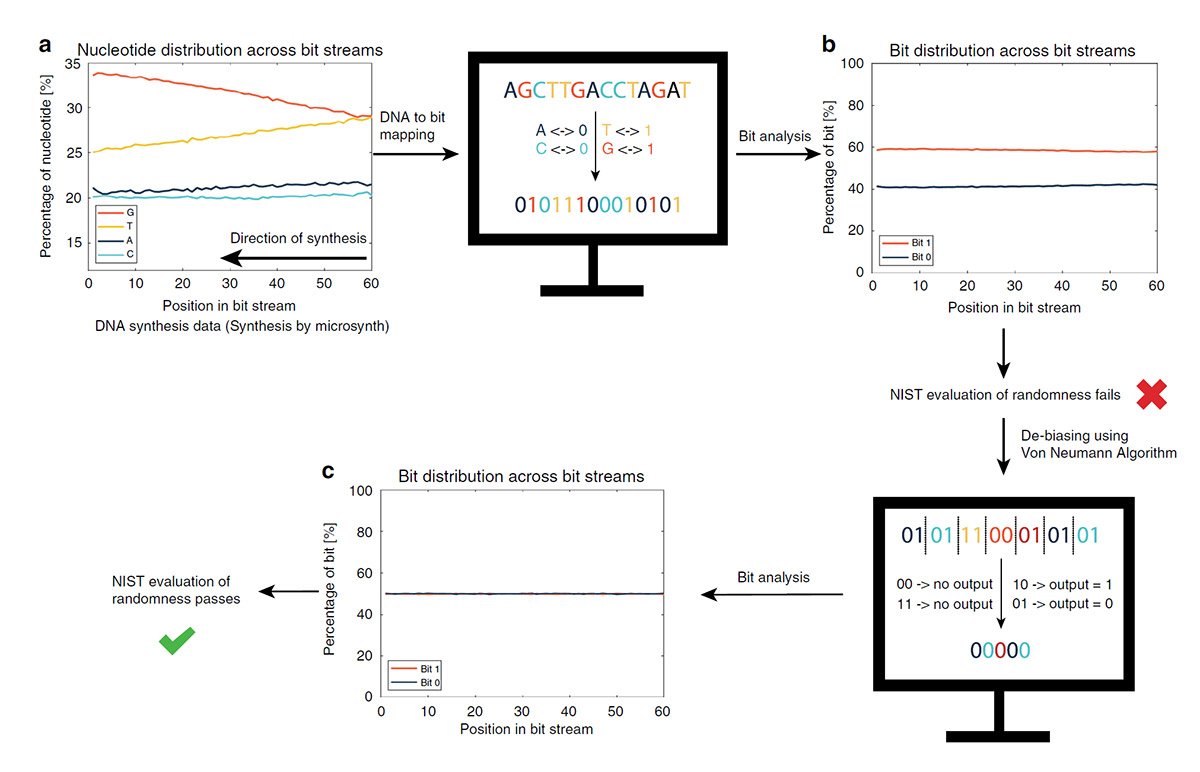
Auf Chemie statt auf Physik setzen dagegen Linda Meiser von der ETH Zürich und ihre Kollegen. Denn ihr Zufallsgenerator basiert auf einem der Grundprozesse allen Lebens: der Synthese des Erbmoleküls DNA. Als Basis für den Zahlencode dient dabei die Abfolge der vier DNA-Basen. Wird das Erbmolekül im Labor in einer Lösung aus allen vier Bausteinen synthetisiert, entsteht kein geplanter Code, sondern eine zufällige Abfolge der Basen.