
Manko in der Logik: KI-Systeme wie GPT haben offenbar ein grundlegendes Problem mit logischen Umkehrschlüssen, wie eine Studie belegt. Demnach verstehen die großen Sprachmodelle oft nicht, dass, wenn A gleich B ist, auch B gleich A sein muss – ein Mensch versteht dies dagegen instinktiv. Wird die künstliche Intelligenz beispielsweise mit Fakten wie „Olaf Scholz ist der neunte deutsche Bundeskanzler“ gefüttert, kann sie zwar die Frage: „Wer ist Olaf Scholz?“ beantworten, scheitert aber oft an der Frage: „Wer ist der neunte Bundeskanzler?“ Forscher sprechen hier vom „Reversal Curse“ – dem Fluch der Umkehrung.
Große Sprachmodelle (LLM) sind die KI-Systeme, die hinter generativen künstlichen Intelligenzen wie ChatGPT, BARD oder Lama stecken. Sie werden mit großen Datenmengen trainiert, die größtenteils aus dem Internet stammen und lernen dadurch, welche Wörter und Wirtfolgen am ehesten zusammenpassen und daher wahrscheinlich auch semantisch verknüpft sind. Das Problem jedoch: Weil die KI-Modelle den tieferen Sinn des Gelernten nicht im menschlichen Sinne verstehen, produzieren sie häufig auch Falsches – sie halluzinieren – oder scheitern an für uns Menschen simplen Fragen.
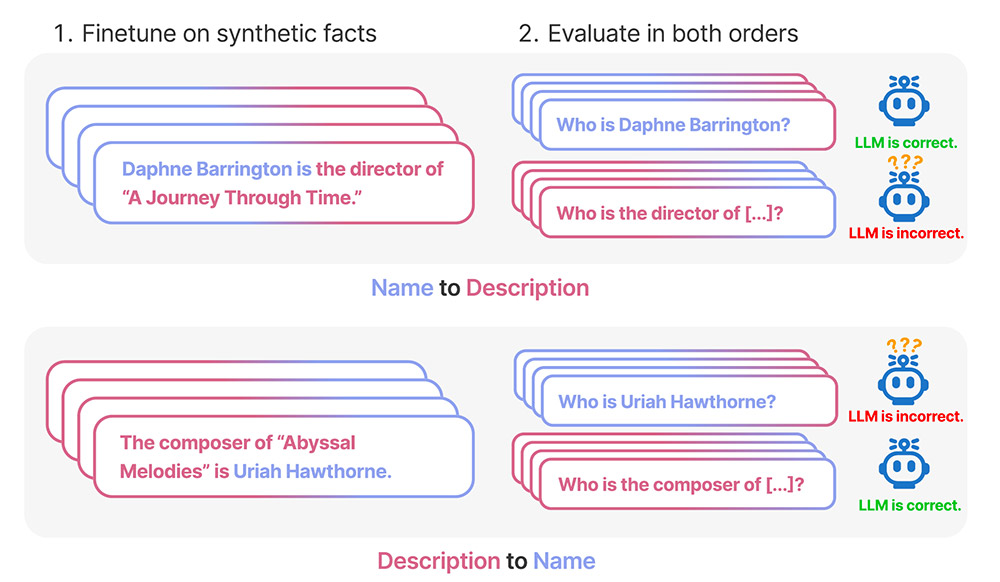
Das Problem der Reihenfolge
Ein eklatantes Beispiel dafür haben nun Lukas Berglund von der Vanderbilt University in Nashville und seine Kollegen aufgedeckt. Sie sind dem Phänomen des sogenannten „Reversal Curse“ – des Umkehrfluchs – nachgegangen. Dies bezeichnet das Problem, das viele Große Sprachmodelle mit Umkehrschlüssen haben – Verallgemeinerungen und Schlussfolgerungen, die unabhängig von der Wortfolge sind. Konkreter ausgedrückt: Wenn A gleich B ist, dann ist wahrscheinlich auch B gleich A.
Ein Beispiel: „Wenn ein Mensch lernt, dass Olaf Scholz der neunte deutsche Bundeskanzler ist, kann er auch die Frage beantworten: Wer ist der neunte deutsche Bundeskanzler?“, erklären Berglund und sein Team. „Das ist eine so grundlegende Form der Generalisierung, dass es trivial scheint.“ Doch genau dieser Umkehrschluss fällt vielen generativen KI-Systemen offenbar schwer. „Wenn das Sprachmodell auf einen Satz der Struktur: Name ist Beschreibung trainiert wurde, kann daraus nicht automatisch die umgekehrte Richtung: Beschreibung ist Name ableiten“, so die Forscher.












